Plotting
Plotting文档。
使用Pandas,Vincent和xlsxwriter在excel文件中生成嵌入图。
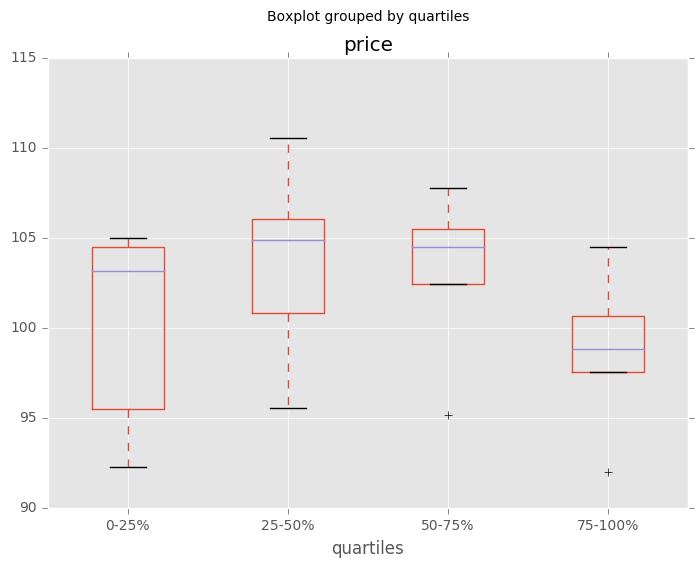
分层变量的四分位数的箱线图
In [162]: df = pd.DataFrame(
.....: {u'stratifying_var': np.random.uniform(0, 100, 20),
.....: u'price': np.random.normal(100, 5, 20)})
.....:
In [163]: df[u'quartiles'] = pd.qcut(
.....: df[u'stratifying_var'],
.....: 4,
.....: labels=[u'0-25%', u'25-50%', u'50-75%', u'75-100%'])
.....:
In [164]: df.boxplot(column=u'price', by=u'quartiles')
Out[164]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff27ea62b90>