Basic Plotting: plot
有关某些高级策略,请参阅cookbook
Series和DataFrame上的plot方法只是plt.plot()的一个简单包装:
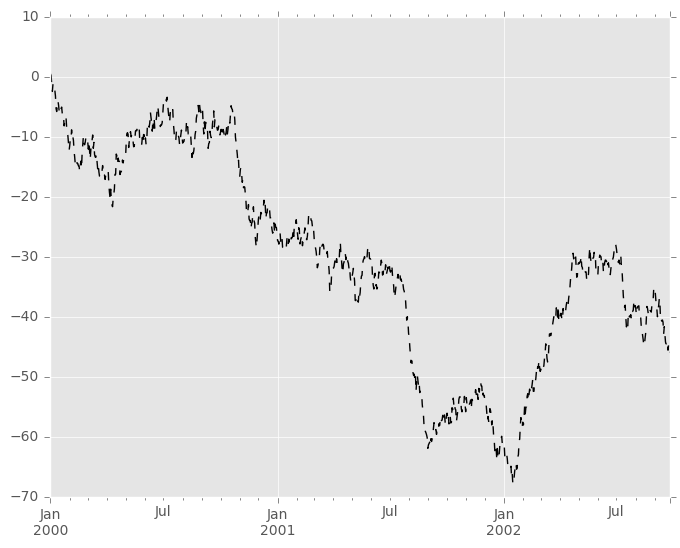
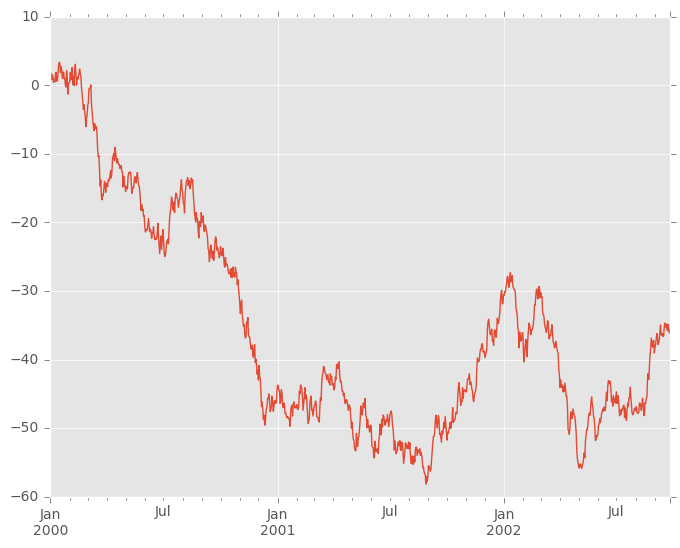
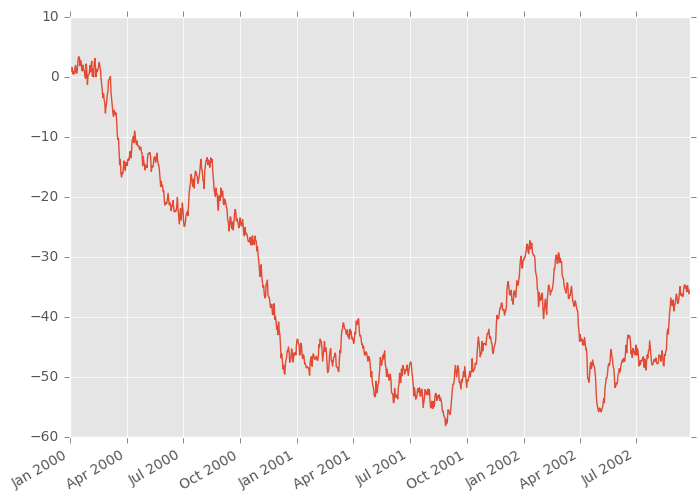
In [2]: ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
In [3]: ts = ts.cumsum()
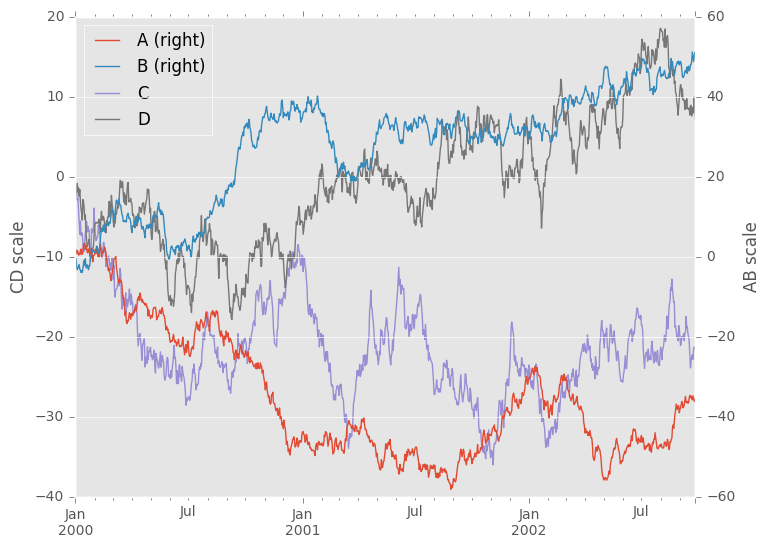
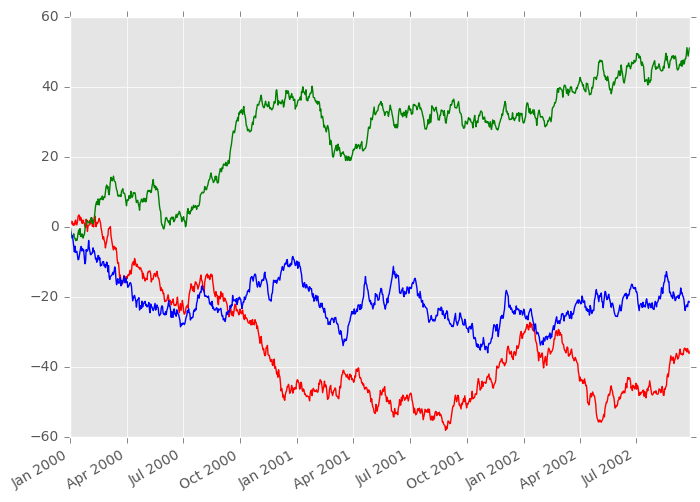
In [4]: ts.plot()
Out[4]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff26d422750>
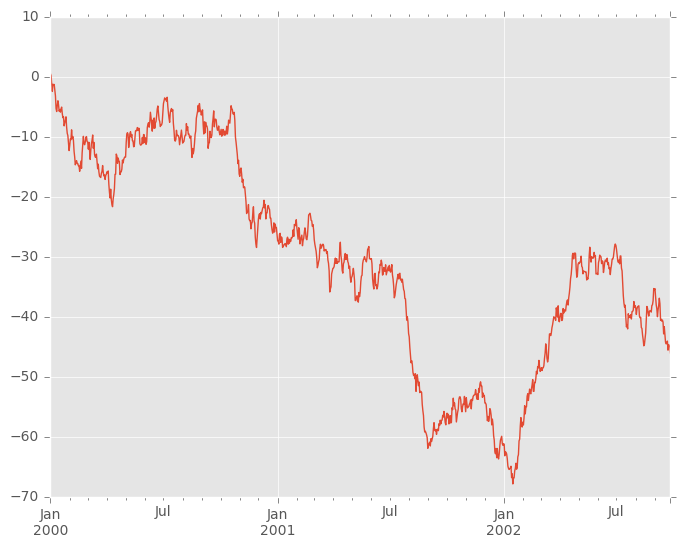
如果索引由日期组成,它会调用gcf().autofmt_xdate()尝试按上述格式很好地格式化x轴。
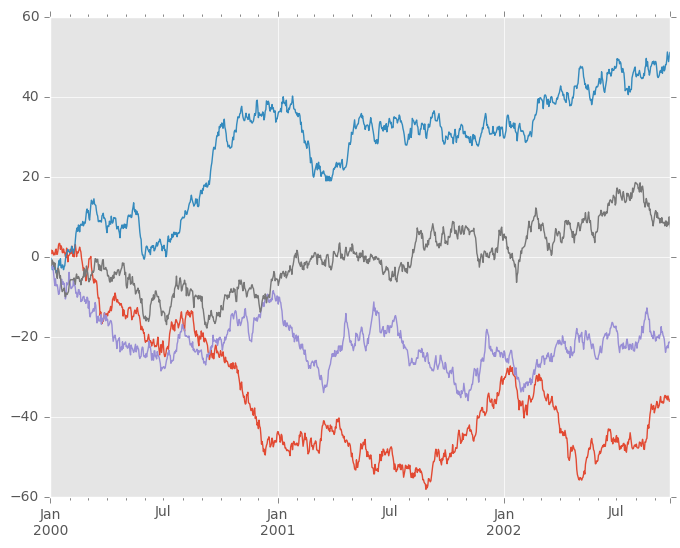
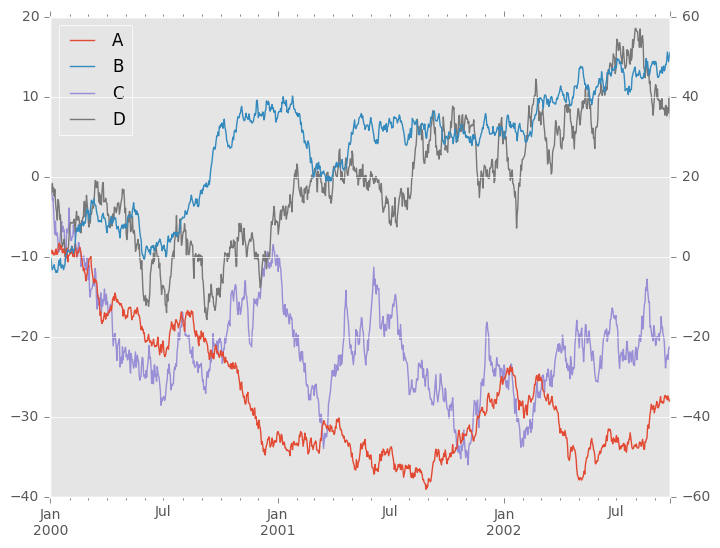
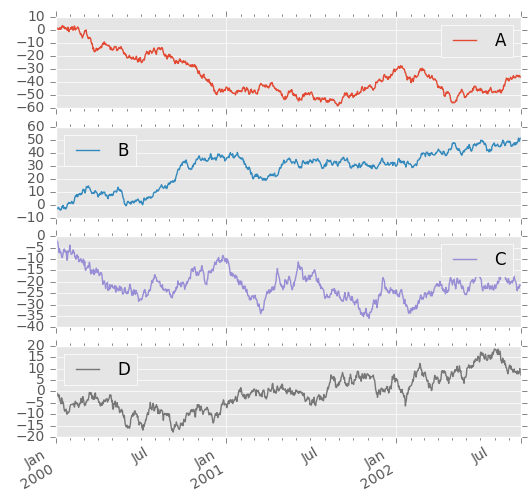
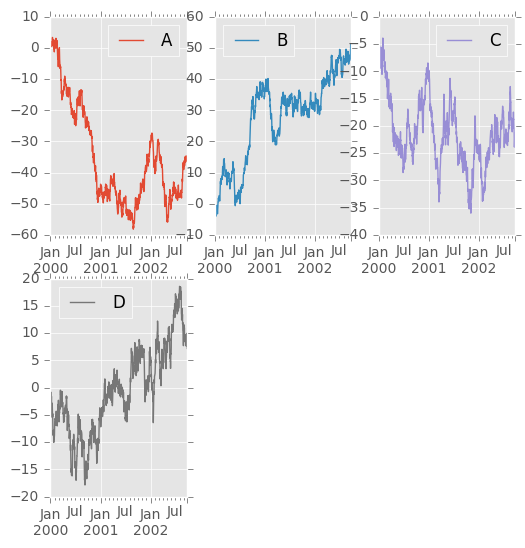
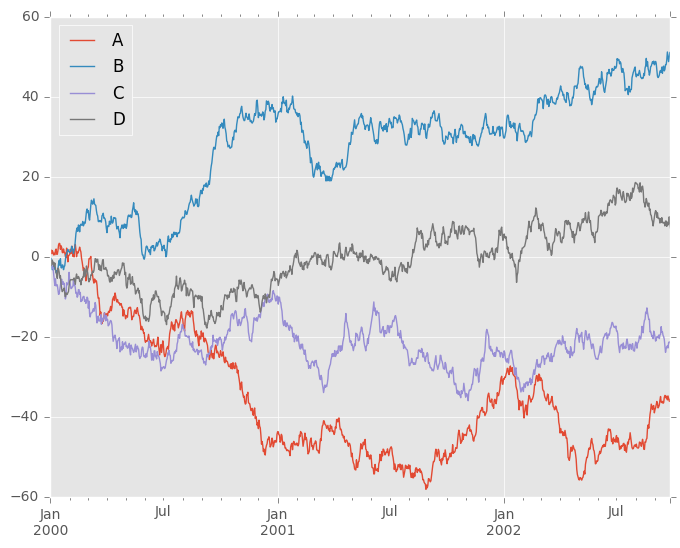
在DataFrame上,plot()是方便绘制所有带标签的列:
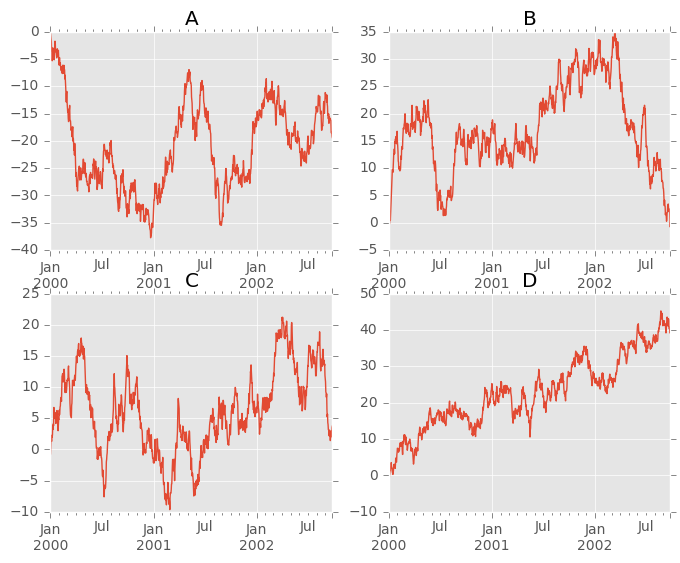
In [5]: df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list('ABCD'))
In [6]: df = df.cumsum()
In [7]: plt.figure(); df.plot();
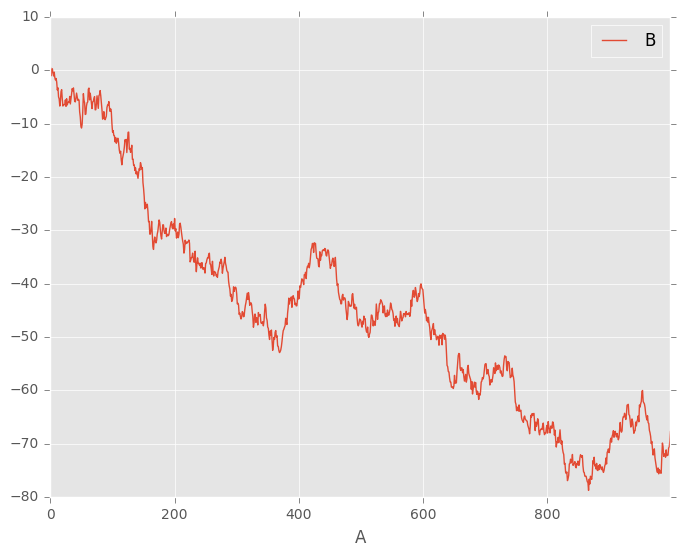
您可以使用plot()中的x和y关键字绘制一列与另一列:
In [8]: df3 = pd.DataFrame(np.random.randn(1000, 2), columns=['B', 'C']).cumsum()
In [9]: df3['A'] = pd.Series(list(range(len(df))))
In [10]: df3.plot(x='A', y='B')
Out[10]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff2667845d0>
注意
有关更多格式和样式选项,请参阅下面的below。
Other Plots
绘图方法允许使用除默认线图外的一些绘图样式。这些方法可以作为plot()的kind关键字参数提供。这些包括:
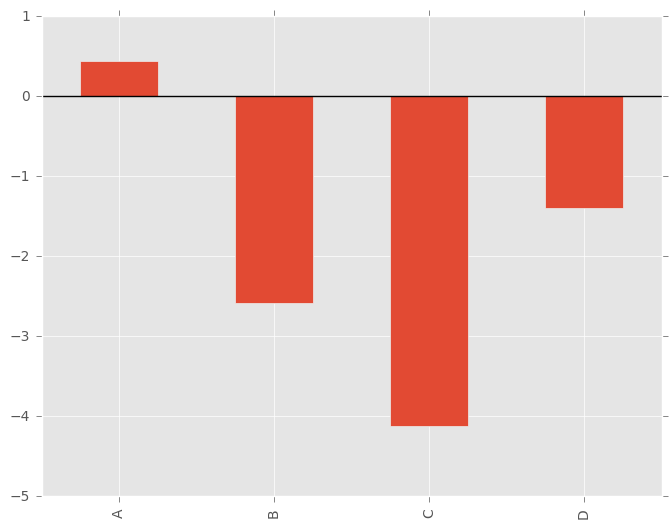
例如,可以通过以下方式创建条形图:
In [11]: plt.figure();
In [12]: df.ix[5].plot(kind='bar'); plt.axhline(0, color='k')
Out[12]: <matplotlib.lines.Line2D at 0x7ff266b33890>
您还可以使用方法DataFrame.plot.<kind>创建这些其他图,而不是提供kind关键字参数。这使得更容易发现绘图方法和他们使用的具体参数:
In [13]: df = pd.DataFrame()
In [14]: df.plot.<TAB>
df.plot.area df.plot.barh df.plot.density df.plot.hist df.plot.line df.plot.scatter
df.plot.bar df.plot.box df.plot.hexbin df.plot.kde df.plot.pie
除了这些kind,还有DataFrame.hist()和DataFrame.boxplot()方法,它们使用单独的接口。
最后,在pandas.tools.plotting中有一些plotting functions,以Series或DataFrame 。这些包括
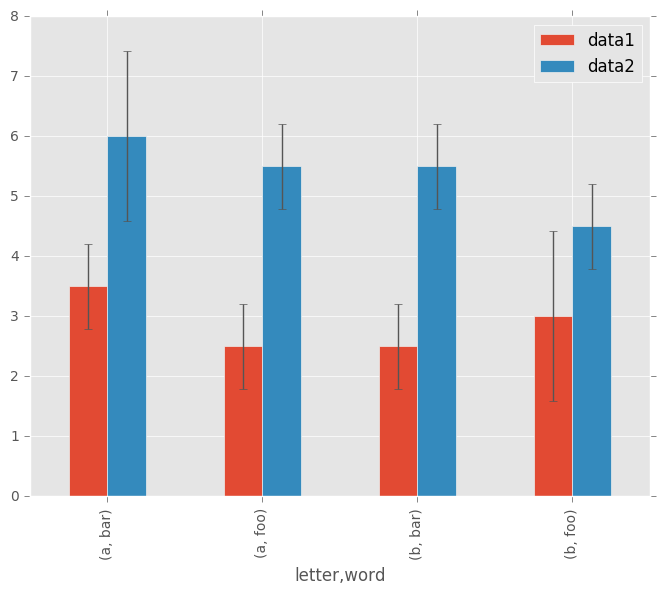
绘图也可以用errorbars或tables来装饰。
Bar plots
对于带标签的非时间序列数据,您可能希望产生条形图:
In [15]: plt.figure();
In [16]: df.ix[5].plot.bar(); plt.axhline(0, color='k')
Out[16]: <matplotlib.lines.Line2D at 0x7ff2673d3510>
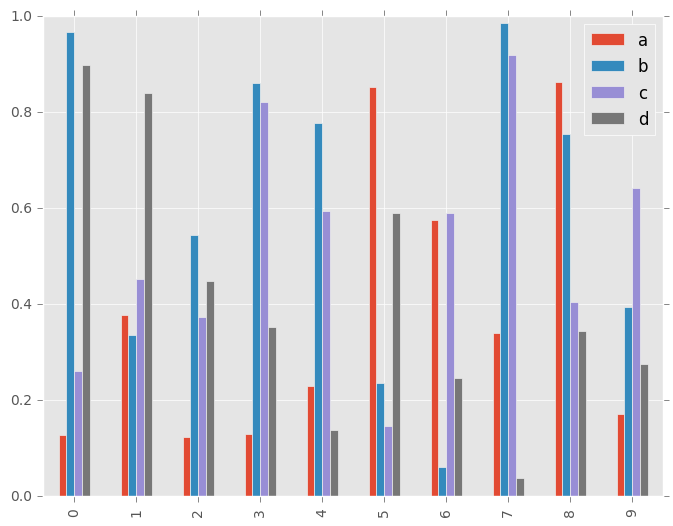
调用DataFrame的plot.bar()方法会产生多条形图:
In [17]: df2 = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
In [18]: df2.plot.bar();
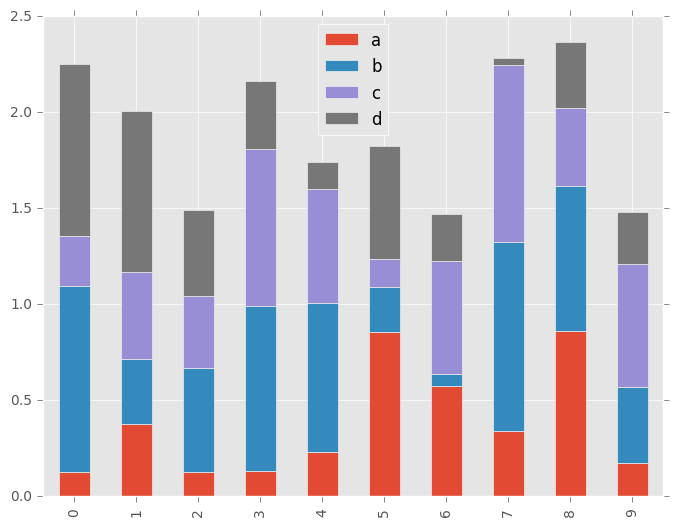
要生成堆叠棒图,请传递stacked=True:
In [19]: df2.plot.bar(stacked=True);
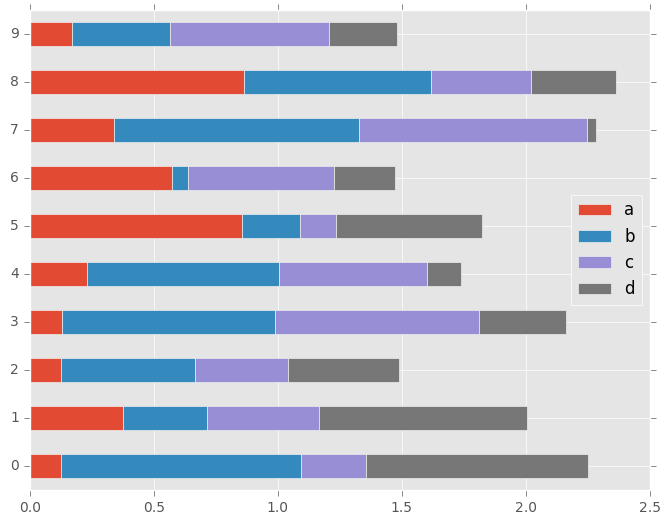
要获取水平条形图,请使用barh方法:
In [20]: df2.plot.barh(stacked=True);
Histograms
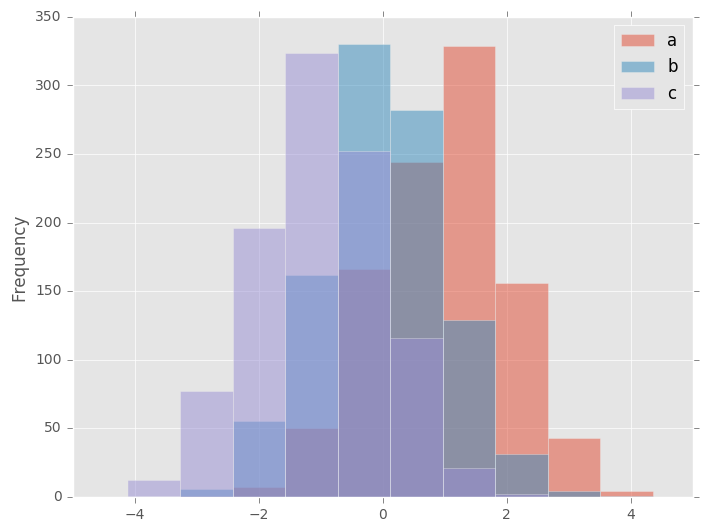
直方图可以使用DataFrame.plot.hist()和Series.plot.hist()方法绘制。
In [21]: df4 = pd.DataFrame({'a': np.random.randn(1000) + 1, 'b': np.random.randn(1000),
....: 'c': np.random.randn(1000) - 1}, columns=['a', 'b', 'c'])
....:
In [22]: plt.figure();
In [23]: df4.plot.hist(alpha=0.5)
Out[23]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff26779c3d0>
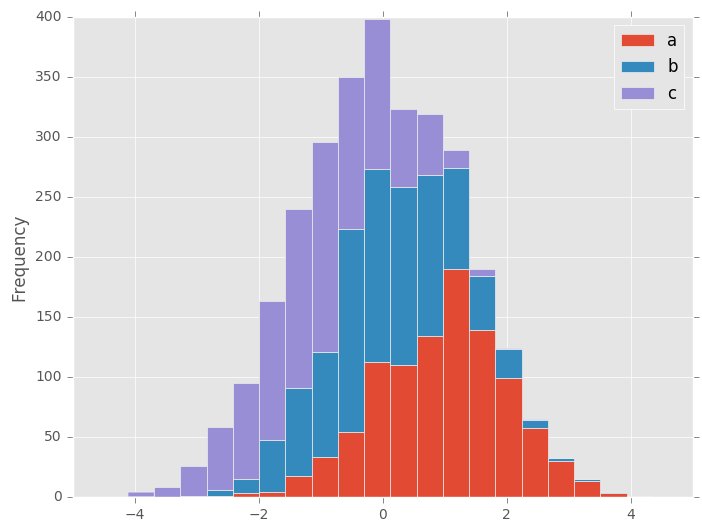
直方图可以通过stacked=True堆叠。Bin大小可以通过bins关键字更改。
In [24]: plt.figure();
In [25]: df4.plot.hist(stacked=True, bins=20)
Out[25]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff26caf76d0>
您可以传递由matplotlib hist支持的其他关键字。例如,水平和累积的histgram可以通过orientation='horizontal'和cumulative='True'来绘制。
In [26]: plt.figure();
In [27]: df4['a'].plot.hist(orientation='horizontal', cumulative=True)
Out[27]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff26c2c89d0>
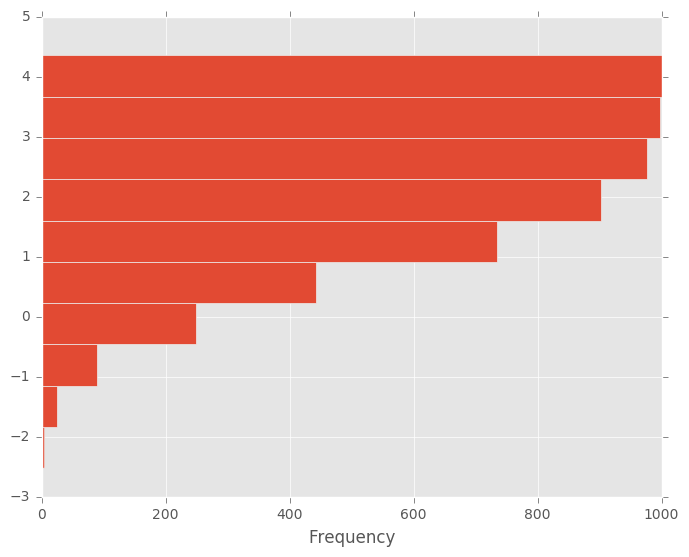
有关更多信息,请参阅hist方法和matplotlib hist文档。
现有的界面DataFrame.hist仍然可以使用绘制直方图。
In [28]: plt.figure();
In [29]: df['A'].diff().hist()
Out[29]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff2770919d0>
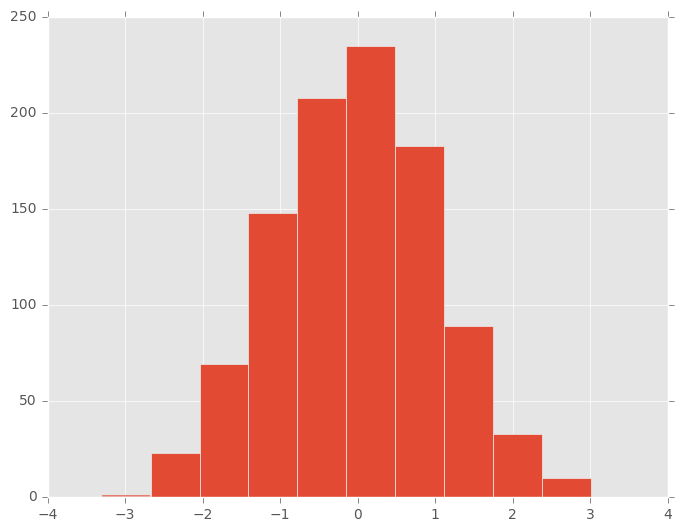
DataFrame.hist()在多个子图上绘制列的直方图:
In [30]: plt.figure()
Out[30]: <matplotlib.figure.Figure at 0x7ff26d67c090>
In [31]: df.diff().hist(color='k', alpha=0.5, bins=50)
Out[31]:
array([[<matplotlib.axes._subplots.AxesSubplot object at 0x7ff2726264d0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7ff2667c8390>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7ff266667a50>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7ff2671545d0>]], dtype=object)
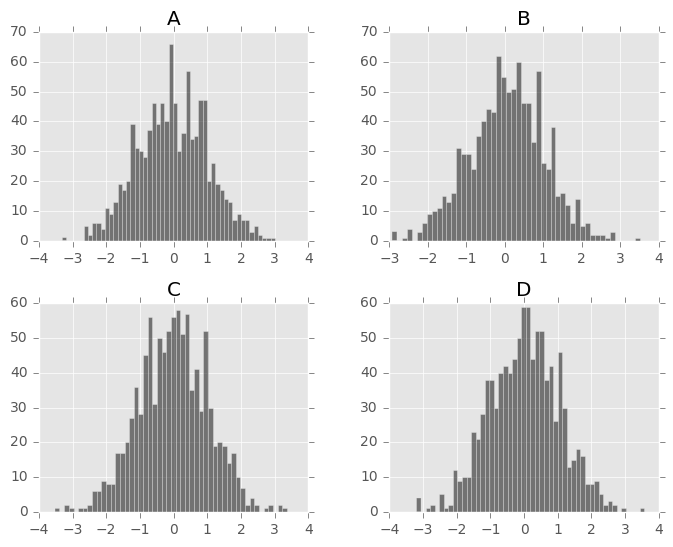
可以指定by关键字绘制分组的直方图:
In [32]: data = pd.Series(np.random.randn(1000))
In [33]: data.hist(by=np.random.randint(0, 4, 1000), figsize=(6, 4))
Out[33]:
array([[<matplotlib.axes._subplots.AxesSubplot object at 0x7ff266750690>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7ff26c71e110>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7ff26735f750>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7ff26c2fe650>]], dtype=object)
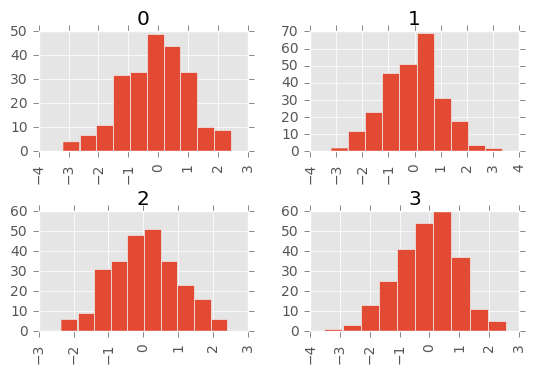
Box Plots
Boxplot可以绘制为调用Series.plot.box()和DataFrame.plot.box()或DataFrame.boxplot()每列中的值的分布。
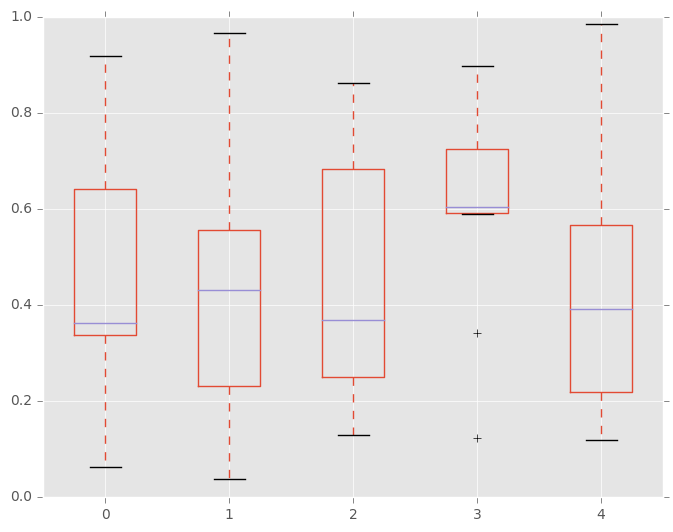
例如,这里是一个箱线图,表示在[0,1]上的一个均匀随机变量的10次观察的五次试验。
In [34]: df = pd.DataFrame(np.random.rand(10, 5), columns=['A', 'B', 'C', 'D', 'E'])
In [35]: df.plot.box()
Out[35]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff27132a050>
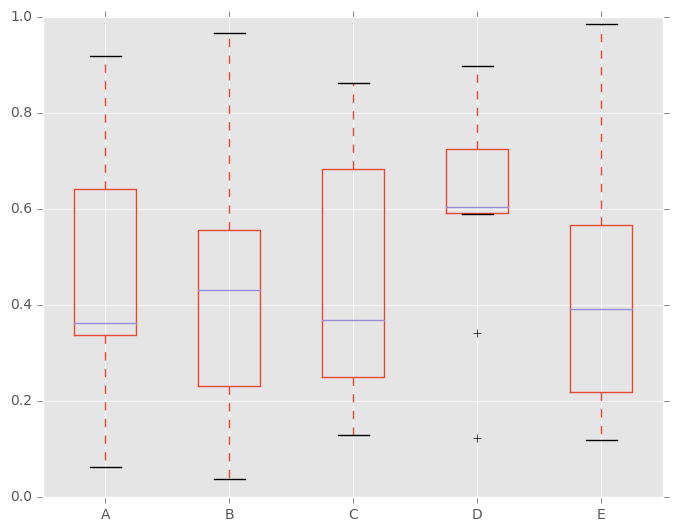
Boxplot可以通过传递color关键字来着色。您可以传递boxes,whiskers,medians和caps的dict如果dict中缺少某些键,则默认颜色将用于相应的艺术家。此外,boxplot还有sym关键字来指定flier样式。
When you pass other type of arguments via color keyword, it will be directly passed to matplotlib for all the boxes, whiskers, medians and caps colorization.
颜色应用于每个要绘制的框。如果您想要更复杂的着色,可以通过传递return_type来获取每个绘制的艺术家。
In [36]: color = dict(boxes='DarkGreen', whiskers='DarkOrange',
....: medians='DarkBlue', caps='Gray')
....:
In [37]: df.plot.box(color=color, sym='r+')
Out[37]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff26c76b890>
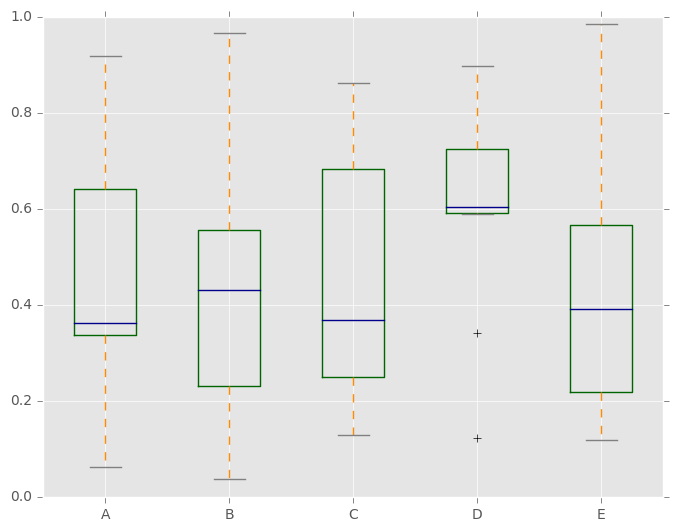
此外,您可以传递由matplotlib boxplot支持的其他关键字。例如,水平和自定义盒线图可以由vert=False和positions关键字绘制。
In [38]: df.plot.box(vert=False, positions=[1, 4, 5, 6, 8])
Out[38]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff26c1f2dd0>
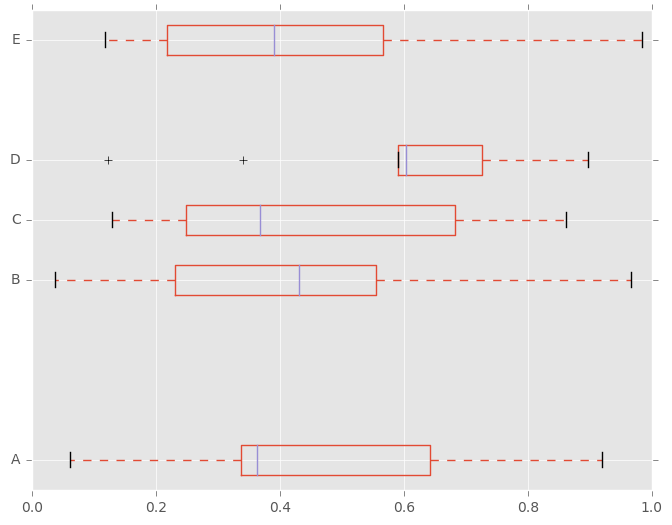
有关更多信息,请参阅boxplot方法和matplotlib boxplot文档。
现有的接口DataFrame.boxplot仍然可以使用绘图箱图。
In [39]: df = pd.DataFrame(np.random.rand(10,5))
In [40]: plt.figure();
In [41]: bp = df.boxplot()
您可以使用by关键字参数创建分层箱形图以创建分组。例如,
In [42]: df = pd.DataFrame(np.random.rand(10,2), columns=['Col1', 'Col2'] )
In [43]: df['X'] = pd.Series(['A','A','A','A','A','B','B','B','B','B'])
In [44]: plt.figure();
In [45]: bp = df.boxplot(by='X')
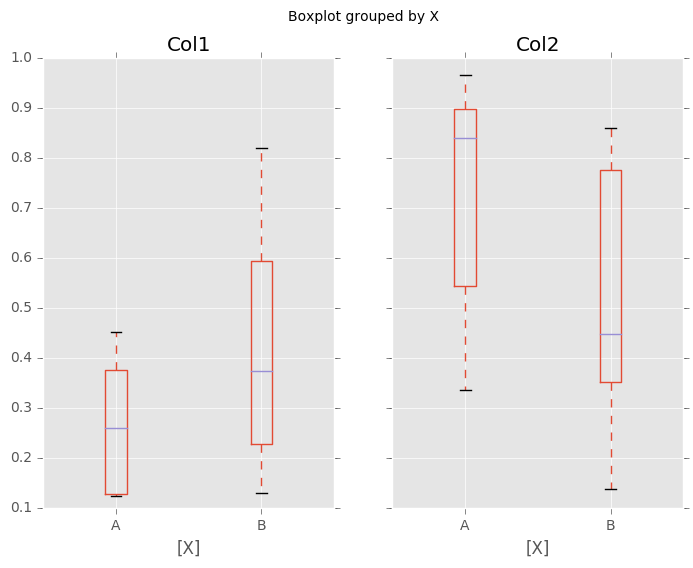
您还可以传递要绘制的列的子集,以及按多个列分组:
In [46]: df = pd.DataFrame(np.random.rand(10,3), columns=['Col1', 'Col2', 'Col3'])
In [47]: df['X'] = pd.Series(['A','A','A','A','A','B','B','B','B','B'])
In [48]: df['Y'] = pd.Series(['A','B','A','B','A','B','A','B','A','B'])
In [49]: plt.figure();
In [50]: bp = df.boxplot(column=['Col1','Col2'], by=['X','Y'])
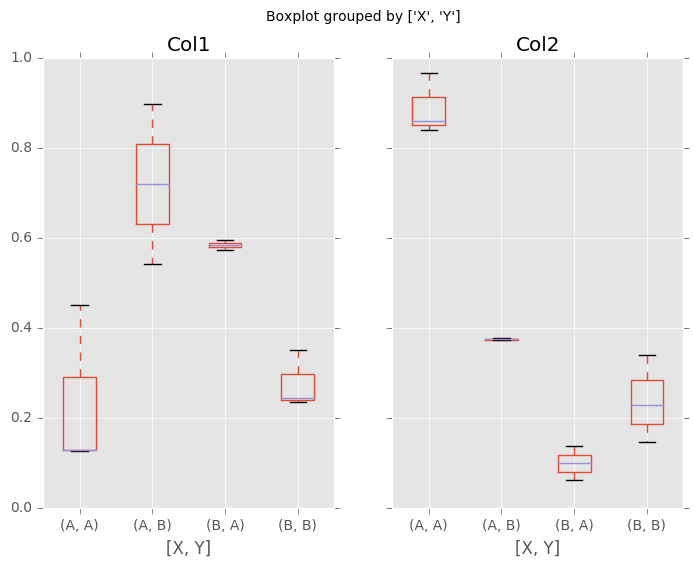
警告
默认值从版本0.19.0中的'dict'更改为'axes'。
在boxplot中,返回类型可以通过return_type关键字控制。有效的选项是{“axes”, “dict”, “both”, None} 。由DataFrame.boxplot与by关键字创建的面,也会影响输出类型:
return_type= |
方面 |
输出类型 |
None |
没有 |
轴 |
None |
是 |
轴的2-D阵列 |
'axes' |
没有 |
轴 |
'axes' |
是 |
系列轴 |
'dict' |
没有 |
艺术家的话 |
'dict' |
是 |
系列的艺术家 |
'both' |
没有 |
namedtuple |
'both' |
是 |
namedtuples系列 |
Groupby.boxplot始终返回一系列return_type。
In [51]: np.random.seed(1234)
In [52]: df_box = pd.DataFrame(np.random.randn(50, 2))
In [53]: df_box['g'] = np.random.choice(['A', 'B'], size=50)
In [54]: df_box.loc[df_box['g'] == 'B', 1] += 3
In [55]: bp = df_box.boxplot(by='g')
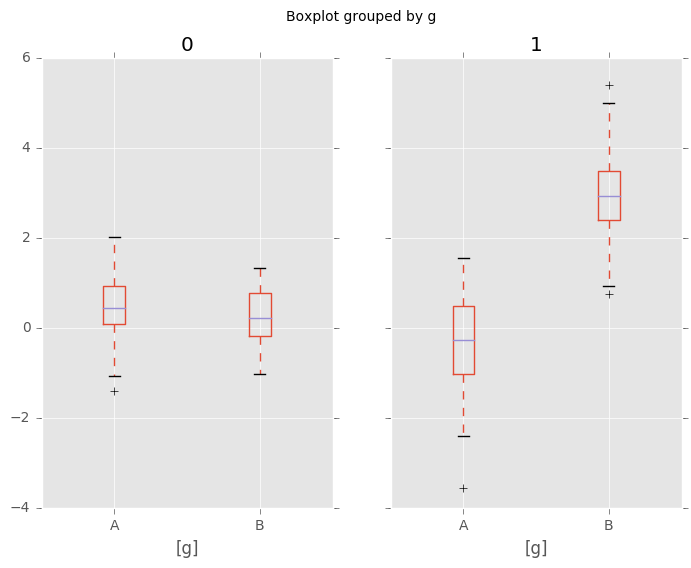
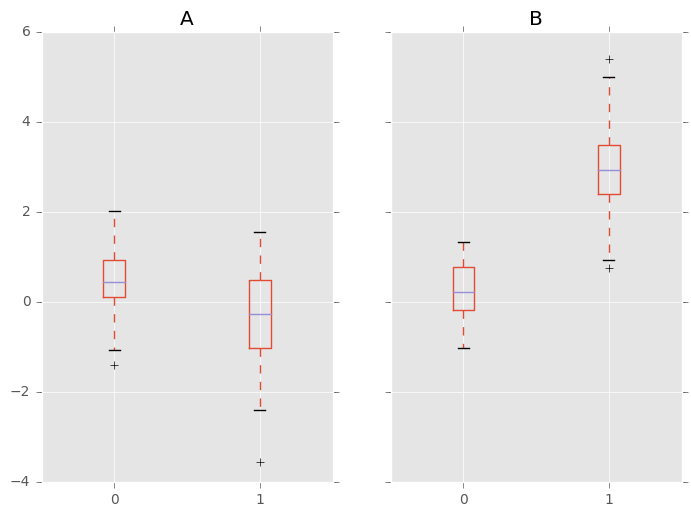
相比于:
In [56]: bp = df_box.groupby('g').boxplot()
Area Plot
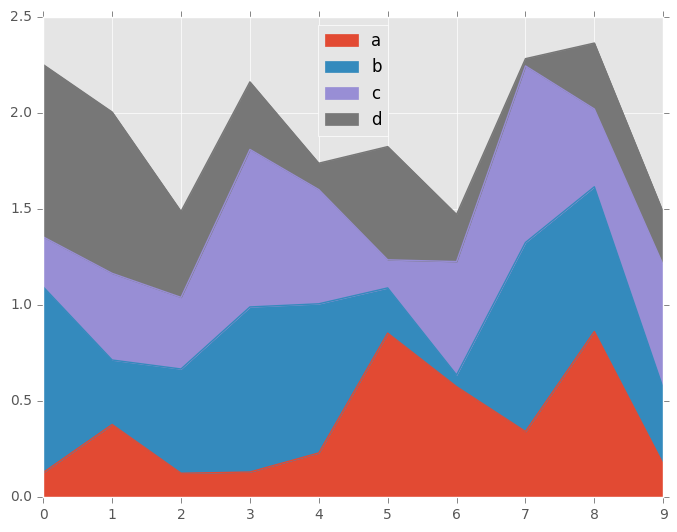
您可以使用Series.plot.area()和DataFrame.plot.area()创建面积图。默认情况下,区域图被堆叠。为了产生堆积面积图,每列必须是正值或全部负值。
当输入数据包含NaN时,它将自动填充0。如果要通过不同的值删除或填充,请在调用plot之前使用dataframe.dropna()或dataframe.fillna()。
In [57]: df = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
In [58]: df.plot.area();
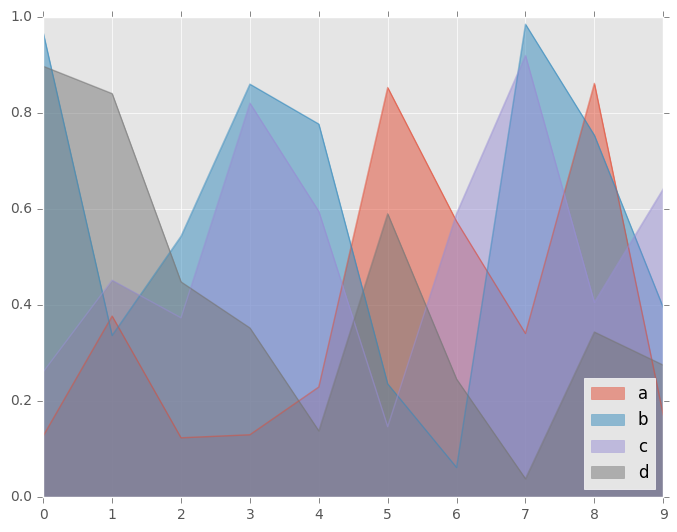
要生成未堆叠的绘图,请传递stacked=False。除非另有说明,Alpha值设置为0.5:
In [59]: df.plot.area(stacked=False);
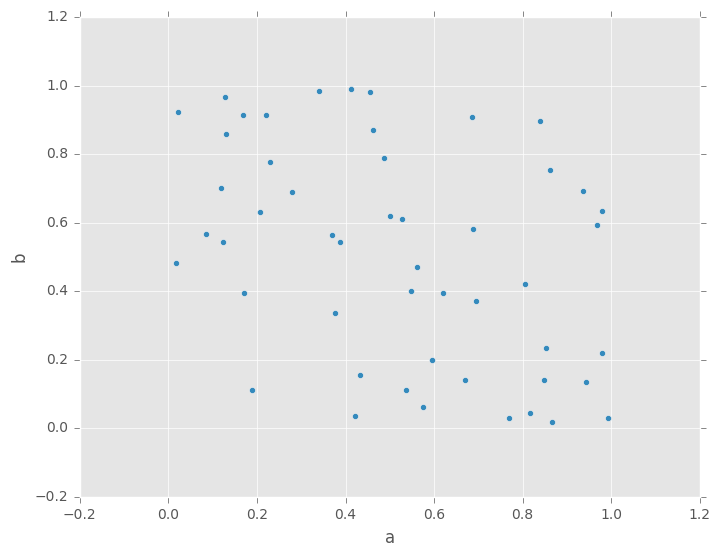
Scatter Plot
散点图可以使用DataFrame.plot.scatter()方法绘制。散点图需要x和y轴的数字列。这些可以由x和y关键字指定。
In [60]: df = pd.DataFrame(np.random.rand(50, 4), columns=['a', 'b', 'c', 'd'])
In [61]: df.plot.scatter(x='a', y='b');
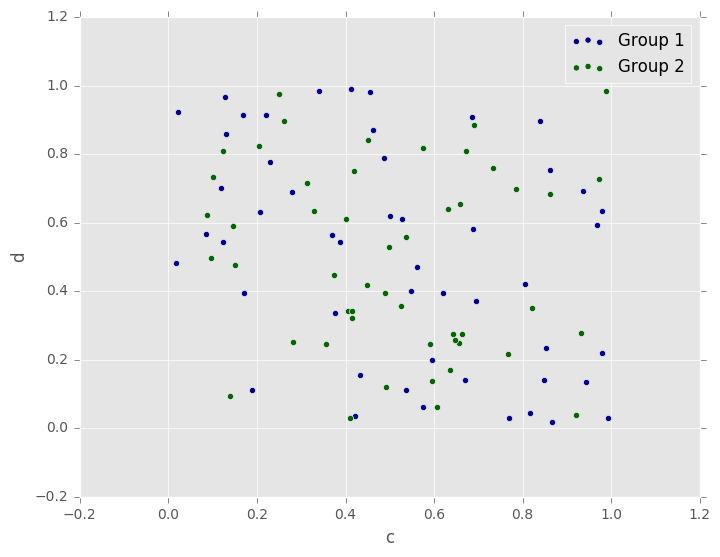
要在单个轴上绘制多个列组,请重复plot方法指定目标ax。建议指定color和label关键字以区分每个组。
In [62]: ax = df.plot.scatter(x='a', y='b', color='DarkBlue', label='Group 1');
In [63]: df.plot.scatter(x='c', y='d', color='DarkGreen', label='Group 2', ax=ax);
可以给出关键字c作为为每个点提供颜色的列的名称:
In [64]: df.plot.scatter(x='a', y='b', c='c', s=50);
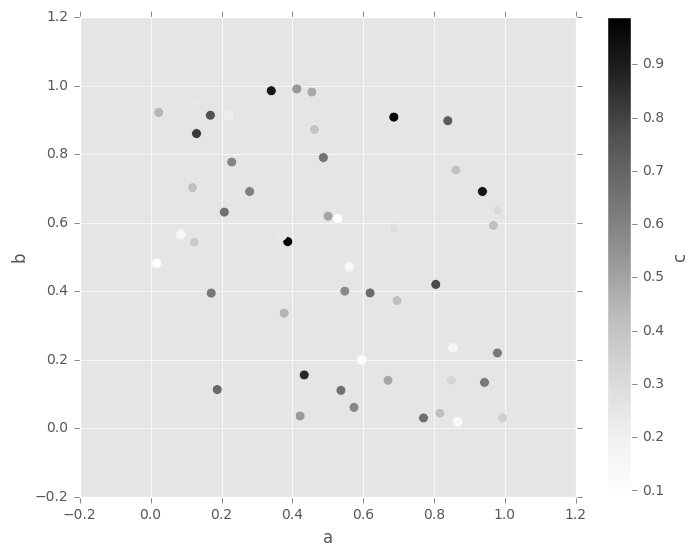
您可以传递由matplotlib scatter支持的其他关键字。下面的示例显示了将气泡大小用于数据框列值的气泡图。
In [65]: df.plot.scatter(x='a', y='b', s=df['c']*200);
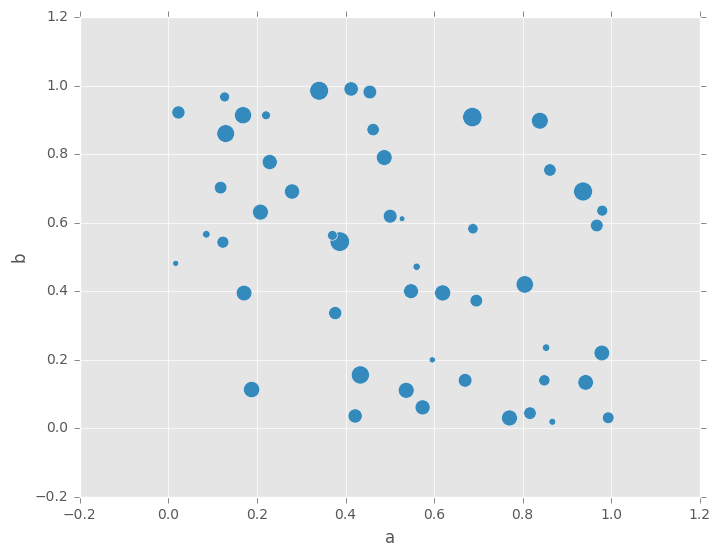
有关更多信息,请参阅scatter方法和matplotlib scatter文档。
Hexagonal Bin Plot
您可以使用DataFrame.plot.hexbin()创建六边形面元图。如果数据太密集,则Hexbin图可能是散点图的有用替代方法,无法单独绘制每个点。
In [66]: df = pd.DataFrame(np.random.randn(1000, 2), columns=['a', 'b'])
In [67]: df['b'] = df['b'] + np.arange(1000)
In [68]: df.plot.hexbin(x='a', y='b', gridsize=25)
Out[68]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff2713ce350>
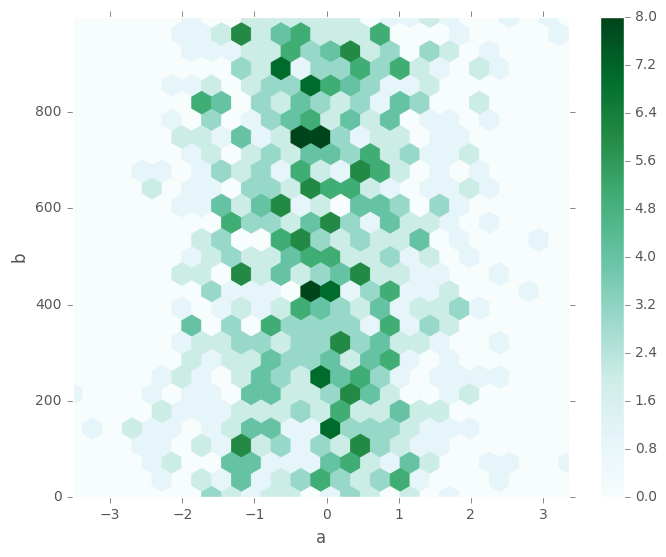
一个有用的关键字参数是gridsize;它控制x方向上的六边形数量,默认为100。较大的gridsize意味着更多,更小的bin。
默认情况下,计算每个(x, y)点的计数的直方图。您可以通过将值传递到C和reduce_C_function参数来指定备用聚合。C指定每个(x, y)点和reduce_C_function将一个bin中的所有值减少为单个数字的一个参数的函数(例如mean,max,sum,std)。在该示例中,位置由列a和b给出,而值由列z给出。这些bin与numpy的max函数聚合。
In [69]: df = pd.DataFrame(np.random.randn(1000, 2), columns=['a', 'b'])
In [70]: df['b'] = df['b'] = df['b'] + np.arange(1000)
In [71]: df['z'] = np.random.uniform(0, 3, 1000)
In [72]: df.plot.hexbin(x='a', y='b', C='z', reduce_C_function=np.max,
....: gridsize=25)
....:
Out[72]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff2669b58d0>
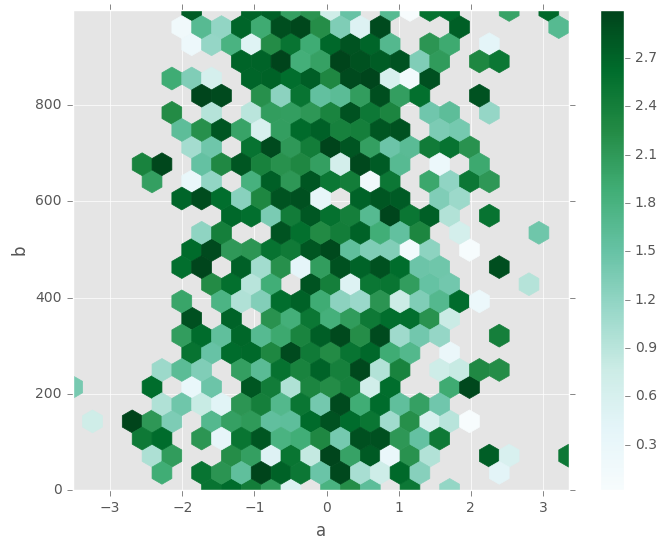
有关详细信息,请参阅hexbin方法和matplotlib hexbin文档。
Pie plot
您可以使用DataFrame.plot.pie()或Series.plot.pie()创建饼图。如果您的数据包含任何NaN,它们将自动填充0。如果数据中有任何负值,则会引发ValueError。
In [73]: series = pd.Series(3 * np.random.rand(4), index=['a', 'b', 'c', 'd'], name='series')
In [74]: series.plot.pie(figsize=(6, 6))
Out[74]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff26c8ac210>
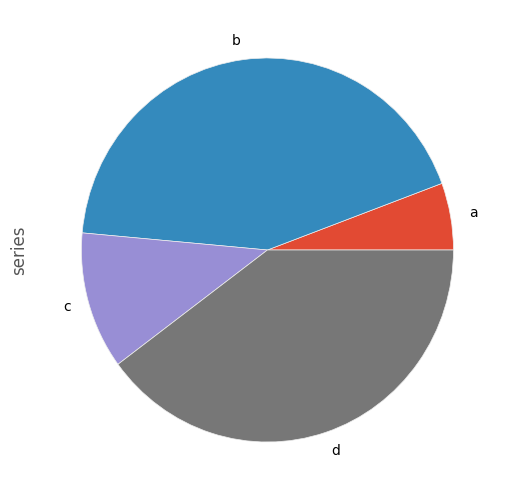
对于饼图,最好使用正方形的数字,一个具有相等的宽高比。您可以通过在返回的axes对象上调用ax.set_aspect('equal')创建具有相等宽度和高度的图形,或强制绘制后的宽高比相等。
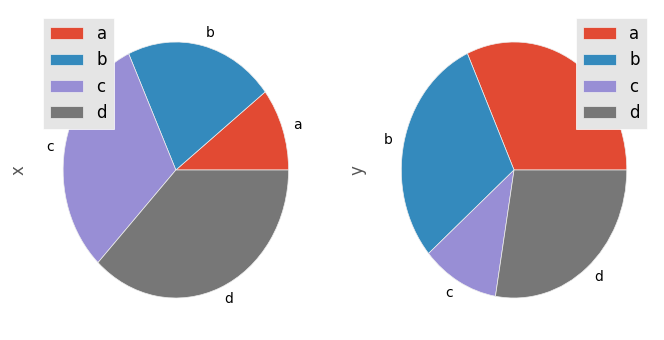
请注意,DataFrame的饼形图需要您通过y参数或subplots=True指定目标列。指定y时,将绘制所选列的饼图。如果指定subplots=True,则每个列的饼图将绘制为子图。默认情况下,每个饼图中将绘制一个图例;指定legend=False以隐藏它。
In [75]: df = pd.DataFrame(3 * np.random.rand(4, 2), index=['a', 'b', 'c', 'd'], columns=['x', 'y'])
In [76]: df.plot.pie(subplots=True, figsize=(8, 4))
Out[76]:
array([<matplotlib.axes._subplots.AxesSubplot object at 0x7ff26c896f50>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7ff26ceb2750>], dtype=object)
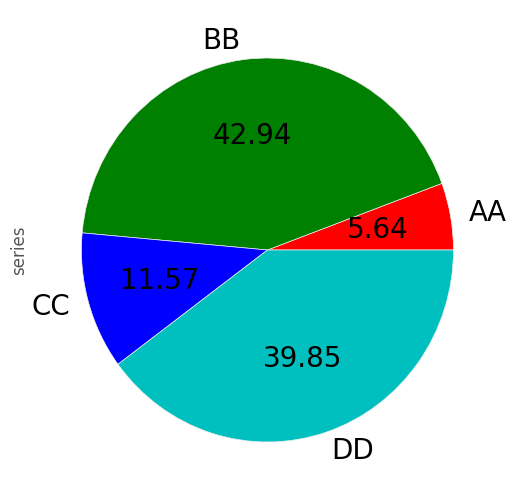
您可以使用labels和colors关键字来指定每个楔形的标签和颜色。
如果您要隐藏楔形标签,请指定labels=None。如果指定fontsize,则该值将应用于楔形标签。此外,还可以使用matplotlib.pyplot.pie()支持的其他关键字。
In [77]: series.plot.pie(labels=['AA', 'BB', 'CC', 'DD'], colors=['r', 'g', 'b', 'c'],
....: autopct='%.2f', fontsize=20, figsize=(6, 6))
....:
Out[77]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff270fede50>
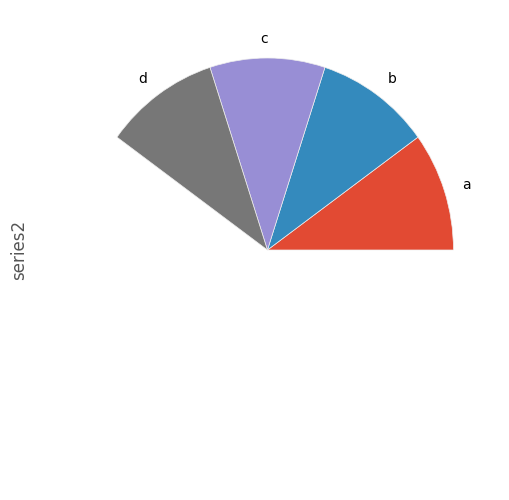
如果传递总和小于1.0的值,则matplotlib绘制一个半圆。
In [78]: series = pd.Series([0.1] * 4, index=['a', 'b', 'c', 'd'], name='series2')
In [79]: series.plot.pie(figsize=(6, 6))
Out[79]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff26c39e9d0>
有关更多信息,请参阅matplotlib饼文档。